Mixture of Experts
1. Definición de Mixture of Experts (MoE)
- Mixture of Experts (MoE) es un enfoque de aprendizaje automático que combina varios modelos o “expertos” para resolver una tarea. En lugar de utilizar un único modelo para hacer predicciones, MoE selecciona y pondera las salidas de varios expertos especializados para diferentes partes del espacio de datos.
- Es un tipo de arquitectura modular donde cada experto se enfoca en una subparte del problema, y un mecanismo de gating determina qué experto(s) deben ser activados para cada caso.
2. Componentes de un Sistema MoE
- Expertos: Son modelos individuales que están especializados en diferentes subespacios del problema. Los expertos pueden ser redes neuronales, árboles de decisión, u otros algoritmos.
- Mecanismo de gating: Es un modelo adicional (generalmente una red neuronal) que decide qué expertos deben activarse para cada entrada de datos. Este mecanismo asigna pesos a los expertos en función de la relevancia de sus predicciones para la tarea específica.
- Combinador: Una vez que el mecanismo de gating selecciona a los expertos relevantes, sus predicciones se combinan ponderadamente para generar la salida final.
3. Proceso General de Funcionamiento
- Entrada de datos: Los datos de entrada se pasan tanto a los expertos como al mecanismo de gating.
- Selección de expertos: El mecanismo de gating analiza los datos y decide qué expertos son los más adecuados para procesarlos, asignando pesos a cada uno.
- Predicción de expertos: Los expertos seleccionados realizan sus predicciones basadas en la entrada.
- Combinación de salidas: Las salidas de los expertos se combinan de acuerdo con los pesos asignados por el mecanismo de gating, generando la predicción final.
4. Ventajas del Enfoque MoE
- Especialización: Al tener expertos especializados en diferentes aspectos del problema, cada uno puede enfocarse en aprender mejor una subparte del espacio de entrada, lo que puede mejorar la precisión y la eficiencia.
- Eficiencia computacional: Dado que solo algunos expertos son activados para cada entrada, MoE puede reducir los costos computacionales en comparación con utilizar un modelo completo en cada predicción.
- Flexibilidad: El sistema es adaptable y modular. Los expertos pueden ser reemplazados, actualizados o ajustados sin necesidad de reconstruir todo el sistema.
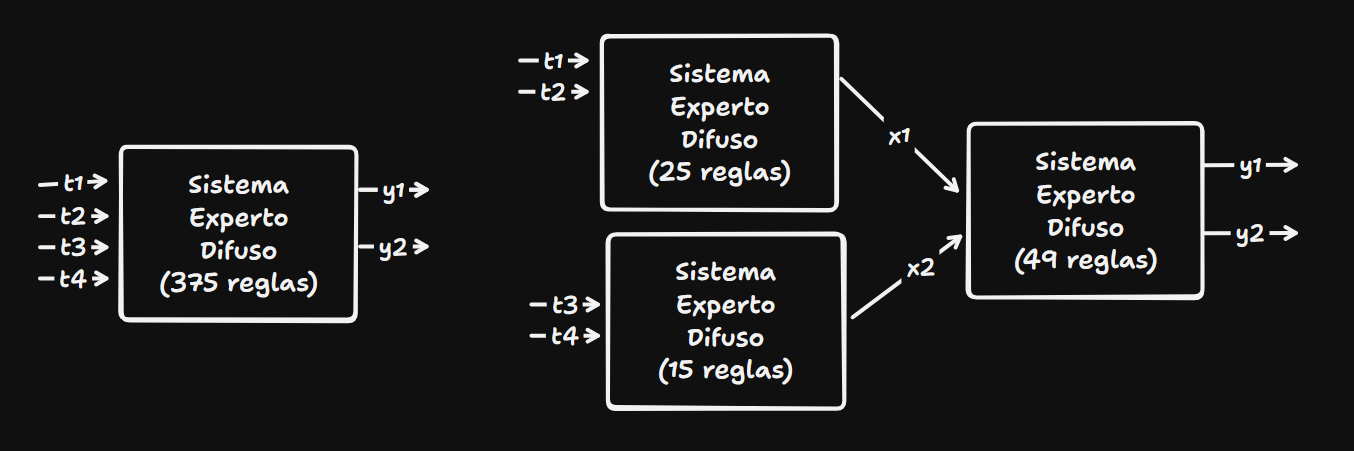
5. Desafíos de MoE
- Entrenamiento del mecanismo de gating: El entrenamiento adecuado del mecanismo de gating es crucial y puede ser complicado. Si el gating no está bien entrenado, podría seleccionar incorrectamente a los expertos.
- Overfitting (sobreajuste): Como cada experto se especializa en una subparte de los datos, existe el riesgo de que los expertos se vuelvan demasiado especializados y no generalicen bien en otras partes del espacio de entrada.
- Balance entre expertos: A veces, algunos expertos pueden dominar el proceso de predicción, mientras que otros se vuelven subutilizados. Esto puede llevar a una especialización ineficaz o a una falta de robustez en el modelo general.
6. Aplicaciones de MoE
- Procesamiento de lenguaje natural (NLP): MoE se ha utilizado en tareas como traducción automática y modelado de lenguaje, donde diferentes expertos pueden especializarse en diferentes aspectos del lenguaje, como sintaxis o gramática.
- Visión por computadora: En tareas de clasificación de imágenes, MoE permite que diferentes expertos se enfoquen en características específicas de las imágenes.
- Sistemas de recomendación: MoE puede combinar diferentes modelos de recomendación, donde cada experto se enfoca en diferentes aspectos del perfil del usuario o del contenido.
- Modelos de inteligencia artificial a gran escala: Modelos de lenguaje grandes, como GPT y otras arquitecturas recientes, han incorporado enfoques MoE para mejorar la escalabilidad y la especialización de ciertas partes del modelo.
7. Entrenamiento de un Sistema MoE
- Retropropagación (Backpropagation): MoE se entrena usando métodos de retropropagación, donde tanto los expertos como el mecanismo de gating se optimizan conjuntamente. La pérdida o error de predicción se distribuye entre los expertos activados y el mecanismo de gating.
- Regularización: Es importante aplicar técnicas de regularización para evitar que los expertos se especialicen en exceso o que el mecanismo de gating favorezca a un solo experto en todas las predicciones.
- Estrategias de optimización: Existen estrategias como entrenamiento jerárquico donde el gating y los expertos se entrenan secuencialmente para mejorar la precisión y eficiencia.
8. Ejemplo de MoE en Redes Neuronales
- Imagina un sistema MoE para reconocer objetos en imágenes. Se pueden tener expertos especializados en reconocer objetos con diferentes formas o colores, mientras que el mecanismo de gating decidirá, basándose en las características de una imagen, cuál de estos expertos debe ser utilizado para hacer la predicción final.
9. MoE en Modelos de Lenguaje a Gran Escala
- En modelos como GPT-3, MoE se utiliza para optimizar los cálculos. En lugar de hacer que todos los componentes del modelo trabajen en cada paso, solo una pequeña cantidad de expertos se activa, lo que permite aumentar la eficiencia y mejorar la especialización sin un costo computacional prohibitivo.